
[TIL] HTTP 요청과 응답 과정
질문 내용
- www.naver.com 으로 접속 시 일어나는 과정 모두를 설명하세요.
질문 목적
- HTTP 요청, 응답은 어떻게 구성되어 있고 브라우저와 클라이언트-서버 상호 작용을 하는가?
- 웹 요청, 응답에서 HTTP 프로토콜의 특징에 대한 이해가 있는가?
- HTTP 프로토콜에 따른 보완책은 어떠한 방법이 있는가?
핵심 포인트
순서
클라이언트가 웹서버에 데이터를 요청하고 웹서버가 클라이언트에 데이터를 응답하는 과정에 대해 자세히 알아보자.
우리가 사용하는 브라우저는 어떻게 HTML 화면을 그려낼까?
API 서버에 데이터를 요청하면 어떻게 데이터를 JSON으로 전달해줄까?
이에 대한 궁금증을 확인하기 위해서 클라이언트와 웹서버간의 데이터 요청 및 응답 과정에 대해 자세히 알아보려한다.

그림1. 웹서버와 브라우저 사이의 요청과 응답 출처 : MDN
먼저 클라이언트(대게 브라우저)와 웹서버 간의 데이터가 어떻게 전달되는 지를 알아보자.
우리는 브라우저를 키면 주소창에 다음과 같은 정보를 입력한다.
www.naver.com
위와 같은 정보를 URI(Uniform Resource Identifier, URI) 또는 URL(Uniform Resource Locator) 이라고 한다.
컴퓨터는 네트워크상 고유한 주소를 갖게 되는데, 이를 IP 라고 한다.
IP (예: 192.168.2.10) 는 쉽게 기억하기가 어려워서 www.naver.com 과 같은 도메인 이름을 갖게 되는데, 이를 사용하여 쉽게 컴퓨터에 연결할 수 있게 되는 것이다.
그림2. Domain Name 과 IP 출처 : MDN
따라서 우리는 쉽게 www.naver.com 라는 Domain Name 만으로 컴퓨터가 네트워크상에 가지고 있는 고유한 주소에 접근할 수 있게 되는 것이다. (이 때 Domain Name ↔ IP 를 변환하는 작업에서 DNS 서버가 있다. )
그럼 브라우저는 www.naver.com 이라는 주소를 입력하면 해당 Domain Name 을 갖고 있는 IP 를 찾아서 자료를 요청하게 된다.
딱 주소를 입력했을 때, 어떤 방식으로 자료를 웹서버에 요청(Request) 하게 되는 지 자세히 살펴보겠다.
방법은 fiddler 라는 툴을 설치하여 진행하였다.
Request 요청에 대해서는 다음과 같은 메세지를 보내게 된다.
GET https://www.naver.com/ HTTP/1.1
Host: www.naver.com
Connection: keep-alive
Cache-Control: max-age=0
sec-ch-ua: " Not;A Brand";v="99", "Google Chrome";v="91", "Chromium";v="91"
sec-ch-ua-mobile: ?0
Upgrade-Insecure-Requests: 1
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9
Sec-Fetch-Site: same-origin
Sec-Fetch-Mode: navigate
Sec-Fetch-User: ?1
Sec-Fetch-Dest: document
Referer: https://www.naver.com/
Accept-Encoding: gzip, deflate, br
Accept-Language: en-US,en;q=0.9,ko;q=0.8
Cookie: NNB=N6ASKDYDV22F6; NM_THEME_EDIT=; NRTK=ag#all_gr#1_ma#-2_si#0_en#0_sp#0; _ga=GA1.2.982549962.1608695239; ASID=709a610300000176cbeb677b00000050; m_loc=59ad03ab095db3f3a7257572bed6cf76dbc03bee1e70b4af818f2e468dd4a2b1; NFS=2; MM_NOW_COACH=1; MM_NEW=1; NaverSuggestUse=use%26unuse; nx_ssl=2; PM_CK_loc=eee71da3132d66625fea42f8f849a853b51680e77a43014da976a8ad0130239d; BMR=s=1626358522062&r=https%3A%2F%2Fm.blog.naver.com%2FPostView.naver%3FisHttpsRedirect%3Dtrue%26blogId%3Dcoocly%26logNo%3D221592446091&r2=https%3A%2F%2Fwww.google.com%2F
Request 부분을 자세히 살펴보자.
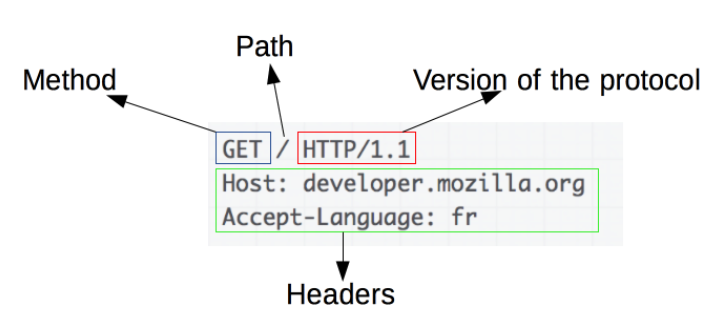
HTTP Request 의 요소 출처 : MDN
GET https://www.naver.com/ HTTP/1.1
HTTP Method 중 하나인 GET Method로 https://www.naver.com/ 의 서버 위치에서 자료를 가져와줘. HTTP/1.1 버전을 사용할게! 라고 요청 메세지를 보냈다.
Connection: keep-alive
서버측에서 keep-alive 에 대한 설정이 지원되면 keep-alive 상태로 줘!
그 외 header 에 해당하는 정보들도 보내며 user-agent 가 무엇인 지 등등의 정보와 함께 Cookie 정보도 넘겨준다.
자주 사용되는 header 에 대해 알아보자면,
- Host : 요청하는 호스트에 대한 호스트명 및 포트번호
- User-Agent : 요청을 보내는 클라이언트의 대한 정보
- Accept : 돌려줄 데이터 타입에 대해 서버에 알림. MIME 타입
- Connection : 서버에 커넥션을 일정시간 잡아둘 수 있는 지 요청
- Content-Type : 리소스의 미디어 타입
- Content-Length: 수신자에게 전송된 엔티티 바디의 크기를 10진수 바이트 단위로 표현
request 에 대한 response 에 대해서 살펴보자
HTTP/1.1 200 OK
Server: NWS
Date: Thu, 15 Jul 2021 14:29:20 GMT
Content-Type: text/html; charset=UTF-8
Transfer-Encoding: chunked
Connection: keep-alive
Cache-Control: no-cache, no-store, must-revalidate
Pragma: no-cache
P3P: CP="CAO DSP CURa ADMa TAIa PSAa OUR LAW STP PHY ONL UNI PUR FIN COM NAV INT DEM STA PRE"
X-Frame-Options: DENY
X-XSS-Protection: 1; mode=block
Content-Encoding: gzip
Strict-Transport-Security: max-age=63072000; includeSubdomains
Referrer-Policy: unsafe-url
<웹페이지에 관련된 소스>
response 구조에 대해 간단하게 설명하면
- Status line
- header
- 공백
- body
HTTP/1.1 200 OK
request 의 요청에 따라 HTTP/1.1 버전으로 HTTP Status Code를 알려준다.
또한 request 의 요청과 마찬가지로 header에 내용을 담아 보낸다.
그럼 웹페이지의 화면은 어떻게 나타나게 된건가?
Content-Type: text/html; charset=UTF-8
<웹페이지에 관련된 소스>
body에 content 가 담기게 되는데 body의 content 는 json, html 등 다양할 수 있다. 현재는 웹페이지에 접근을 요청했고 웹페이지에 대한 html 소스를 넘겨주는 상황이므로 위의 코드를 해석하면 된다. Content-Type 은 text/html 이며 이에 해당하는 정보는 공백으로 구분되어 <웹페이지에 관련된 소스> 라고 넘어올 것이다.
즉 브라우저는 위와 같은 응답구조로 메세지를 받으며 어떠한 종류의 body content 인 지 확인하여 화면을 뿌려주게 되는 것이다.
만약에 API 서버로 요청을 했더라면 어떻게 넘어왔을까? Content-Type이 달라지고 body의 내용에 json이 들어왔을 것이다.
Content-Type: application/json; charset=utf-8
{
"key":"value"
}
위의 예제는 GET Method 에 HTTP Status Code 가 200 OK 로 응답되었다. 다른 것들은 무엇이 있는지에 대해서는 다음의 링크를 통해서 확인하자.
자, 그러면 클라이언트(브라우저)가 웹서버에게 요청하고 응답하는 과정에서 HTTP가 갖는 특징은 무엇일까?
HTTP 의 특징
첫 번째, 단방향성
클라이언트에서 웹서버로 요청을 하게 되는데, 웹서버에서 클라이언트로 요청을 하지는 않는다.
따라서 클라이언트에서 웹서버로 요청을 하는 단방향성 특징이 있다.
두 번째, 비연결성(Connectless)
클라이언트가 HTTP Request 를 웹서버에게 요청하면 웹서버는 response 를 한 후 연결이 끊긴다.
어? 우리는 채팅도 하고 그랬는데?
그건 웹소켓으로 HTTP 프로토콜이 아니고 웹소켓 프로토콜을 사용한다.
따라서 다른 것임을 인지하고 HTTP의 특징으로는 요청 후 응답을 받게 되면 연결이 끊기게 된다는 점을 다시 한번 인지하자.
HTTP는 인터넷 상에서 불특정 다수와 통신 되는 환경을 기반으로 설계가 되어서 적은 리소스로 더 많은 연결을 위하여 비연결성 특징을 가지고 있다.
비연결성으로 인한 단점으로는 서버가 클라이언트에 대하여 연결을 유지하고 있지 않으므로 매 번 새로운 연결 시도/해제의 과정을 거치는데 TCP 기반의 3way-handshake 이 계속 발생하게 된다는 점이다.
HTTP/1.1 버전부터는 이에 대한 오버헤드 리소스를 아끼기 위하여 Request 와 Response 에 대한 설명을 할 때 보여줬던 다음의 방식으로 단점을 보완하고 있다.
Connection : keep-alive
HTTP의 비연결성(connectless) 를 보완하기 위한 keep-alive에 대해서 좀 더 알고싶다면 아래 링크로!
HTTP의 connectless 를 보완하기 위한 keep-alive
세 번째, 무상태성(Stateless)
서버는 클라이언트의 상태를 모른다.
무슨 소리야? 나 로그인하고 장바구니에 상품도 담아봤고… 내 정보들 계속 추적하면서 광고 따라오던데?
HTTP 특징으로는 이 전의 정보나 현재 통신의 상태가 남아 있지 않다.
그럼 위와 같은 일들을 어떻게 가능하게 하고 있을까?
많이 들어봤을 또는 사용했을 쿠키, 세션, 토큰등의 방식으로 클라이언트의 상태를 유지시킬 수 있는 것이다.

Leave a comment